

























-620.svg)

循环智能联合创始人杨植麟:预训练与微调的新范式
-

2021-03-24
-

媒体报道

2021年03月20日,北京智源人工智能研究院举办“智源悟道1.0 AI研究成果发布会”,发布超大规模系列模型“悟道1.0”的阶段性成果。循环智能(Recurrent AI)联合创始人杨植麟博士在会上代表“悟道·文汇”——我国首个具有认知能力的超大规模预训练模型——团队,做了主题为《预训练与微调的新范式》的报告。
本次发布会上同时成立了由 9 位来自学术界和产业界的顶尖科学家组成的“悟道”大模型技术委员会。杨植麟博士与北京大学鄂维南院士、清华大学鲁白教授、中国人民大学人工智能信息学院院长文继荣教授等一道成为委员会成员,负责为大模型研发的技术方案和路线选择等进行指导和把关。
超大规模预训练语言模型仍需朝着多种不同方向进行探索。除了面向“认知”方向的“悟道·文汇”模型,循环智能还启动了 NLP Moonshot 计划,面向金融、教育、房产等 toB 产业应用方向,训练超大规模中文预训练语言模型,最大化 NLP 在产业应用的价值。

循环智能 NLP Moonshot 小组欢迎更多人才加入,推动技术在真实世界产生更大的影响力。
图文回顾
杨植麟:之所以要做认知,和我们文汇小组的定位使命有关系。
第一,我们从一开始就想做有世界影响力的工作。不光是简单地去复刻GPT-3或者BERT,而是在这基础上创新,解决最难的问题,这可能是我们去做这个工作的意义所在。
第二,我们要探索智能的边界。现在有不少超大规模的千万亿模型,但是很多问题是没有办法解决的,在认知问题没有解决前,我觉得其实还是很有多的事情需要学术界和工业界一起探索和解决。
01
我们离认知还有多远:通用、知识、可控
说到认知,我觉得可以简单举几个例子。
比如说,我们能否有一个机器自动地阅读产品需求文档,直接写出代码,把需求开发出来?
或者,能不能有一个通用的对话机器人,通过语言的交互完成很多现实任务?
短期内要做到这些东西需要达到三个目标:
第一、通用。如果一个模型只能简单地做一两个任务,或者只能做特定类型的任务,我认为是没有办法实现认知。
第二、知识。如果模型没有知识,在很多现实任务里就很难取得比较好的结果,很多现实任务需要结合知识才能做。
第三、可控。想让模型完成一个任务,得有办法指挥它,给这个模型一个明确地指令,让它产生想要的状态和行为。

长期目标,我们希望从预测去构造决策,包括完全解决少样本问题,现在少样本的很多任务上,实际上最好的方法,仍然跟我们使用大样本的情况有很大差距,有时候是10个点,有时候是二三十个点,差距就会导致少样本不能用,现在的模型无法建立一个完整的知识体系或者持续做这样的学习,所以接下来做的事情是对预训练和微调模式的创新,进一步接近认知目标。
今天想跟大家分享一下我们在这方面做的工作和一些最新的进展,主要集中在短期目标上,包括通用、知识和可控。

02
预训练框架的通用性问题
通用,我们会从底层提出新的预训练框架,去解决通用的问题,上层我们是用更好的算法,让预训练出来得到的模型,能够去更好地挖掘里面的知识,以及更可控的去使用这样的模型。首先我会讲一讲从通用的角度,预训练框架如何提升。
相关论文 All NLP Tasks are Generation Tasks: A General Pretraining Framework 的主要贡献者是杜政晓、钱雨杰、刘潇、丁铭、裘捷中、杨植麟、唐杰。(论文地址:arxiv.org/abs/2103.10360)

现在我们的NLP领域,主要解决的问题主要可以分为三类:
一种是基于分类或者理解任务,或者叫NLU任务,包括阅读理解和情感分类,或者判断两个句子是不是同一个意思,会归为一大类;
第二类任务,就是有条件的生成模型,比如想做一个摘要,或者想做一个翻译,根据某种输入,去对模型做一个微调,去生成我想要的东西;
第三种任务,是无条件的生成或者语言模型,在没有经过继续训练的情况下,它可以持续的生成。
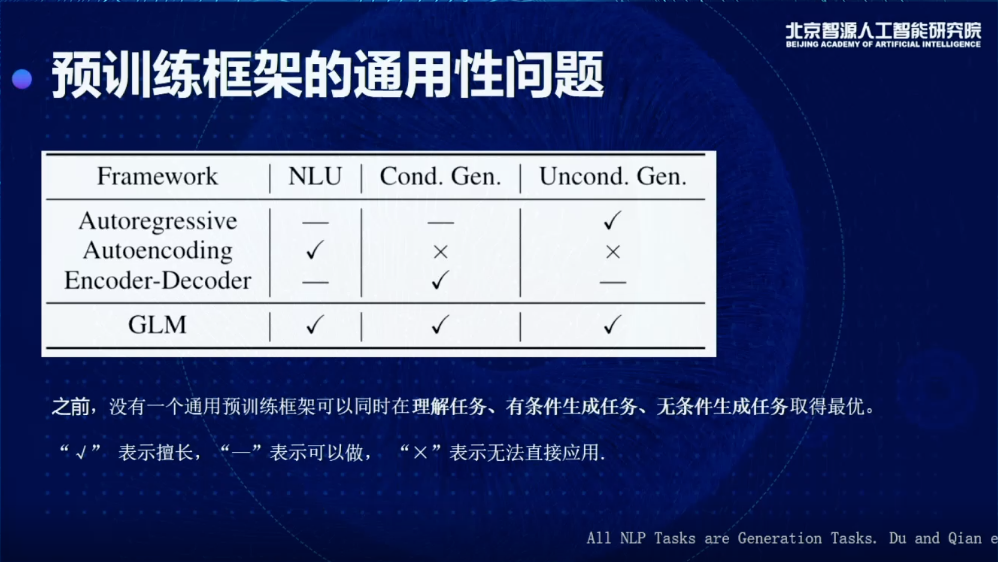
方法层面又分为三种:
一种是自回归的模型,比如GPT,它的特点是非常擅长做第三类任务,即无条件生成任务,做有条件的生成任务,可以做,但是效果没有BERT那么好,比如在Few-shot SuperGLUE上面,用一个GPT,1700亿参数,最后做出来的效果,用2亿的模型微调一下就会比它效果好,几个月前有一个叫做PET的工作有这样的数据对比,其他的数据集也可以观察到这种情况,自回归的模型其实做前两个任务的效果不太好。
对于自编码模型,最擅长的就是做分类理解的任务,但是生成基本完全不行。
还有一种是谷歌训练新提出的,叫做Decoder-Encoder,比如T5模型。它的问题就是三个都可以做,但是至少有两个做得不太好,分类理解和无条件的生成做得不太好。如果是一个非常高级的认知智能体,不可能只能做一个事情,其他的事情都做不了,好比建钢厂,我们希望钢做出来应用到很多的场景,而不仅局限于造一小部分的物件,所以这是我们整个工作的出发点。
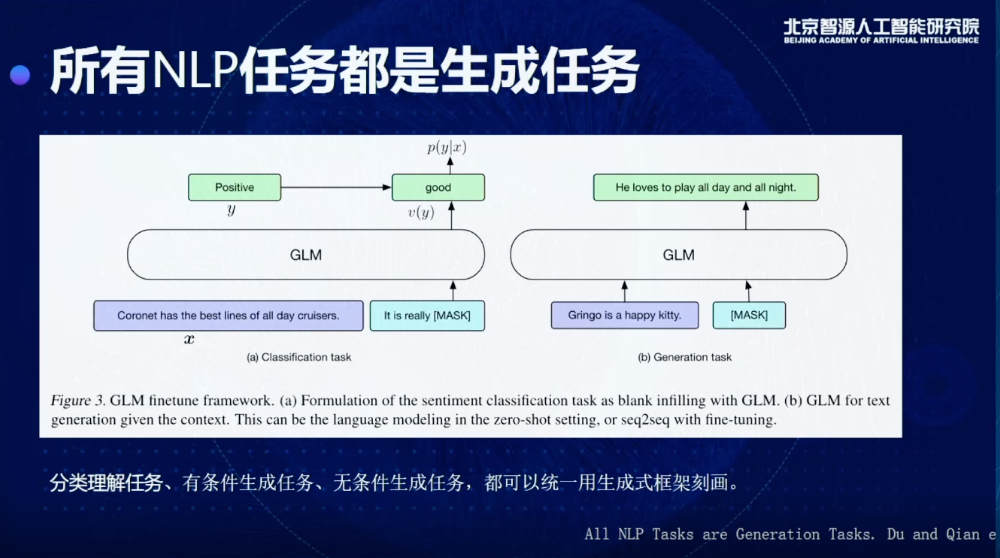
基于这个出发点,我们观察到一个现象,就是几乎所有的NLP任务都可以表达成一个生成任务。为什么呢?我们可以把三个任务做一个区分,有条件和无条件生成,可以被绑定到右边图的框架里(上图),我给这个模型一个提示或者不给提示,让它做生成,实际就是一个生成的框架。
比较难的问题是,对于这种分类和理解的任务怎么用生成任务定义,之前的工作提出了一些想法,其实可以把一个分类或者理解的问题,转换成一个生成的问题。怎么做呢?比如说现在我想知道这句话的情感到底是正还是负,其实可以让它去生成,比如说这个东西是good,就是一个正向的情感,如果是really bad,就是一个负向的情感,所以通过这种方式可以把所有的任务转换成生成任务。
所有的任务都是生成任务,我们就可以在预训练的时候,直接用生成的方式去做预训练,生成的方式是我们在整个序列里面内嵌了很多Decoder,每次mask掉一些东西,通过在Encoder里面嵌入Decoder结构完成这样一个生成。
同时我们也可以做多任务训练,不光把中间的东西生成出来,还可以把末尾的东西,比如50%或者100%作为我们的生成目标,就可以同时去做很多不同的任务,也可以同时在很多下游任务上得到比较好的结果。

这是一个更具体的细节,比如说我现在给到一个输入,x1到x6,我们会先做一个事情,这一步其实比较类似传统的BERT做法,我们会从里面抽取一些我们的目标,比如这里抽出来的是x3、x5、x6,这三个,我会进行一个随机打乱,比如把x5,x6放在前面,或者x3放在后面。
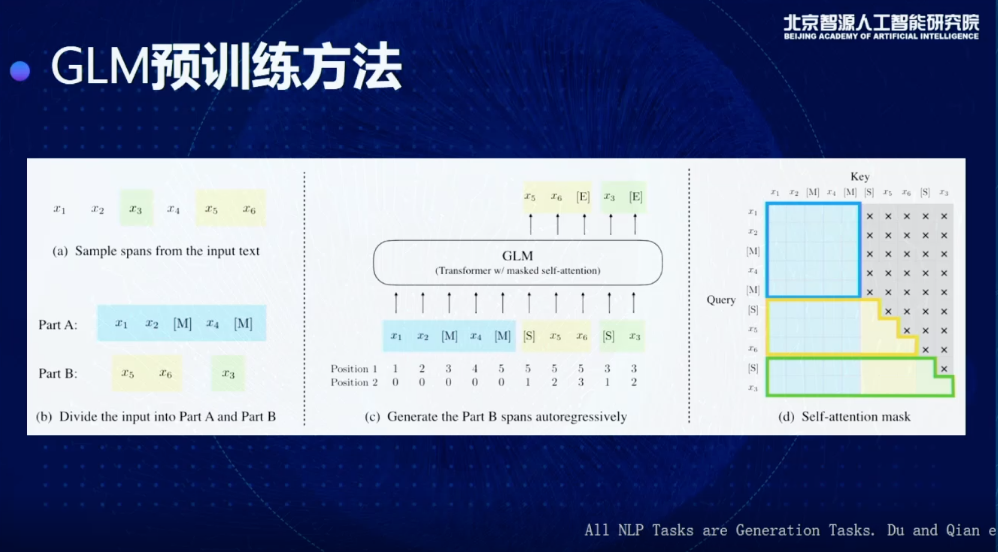
有了这个东西以后,我就去生成后面我想要的东西,通过加入position encoding和Masking的方法,相当于是在Encoder嵌入一个Decoder,这是在标准的SuperGLUE上得到的结果,我们会把所有的模型结果分为三类,这里面每一类都具有一个相似的训练量,比如说 T5-Base,T5-Large,RoBERTa-Large,在一样的训练量情况我们做一个比较,就可以发现,虽然它是一个生成的模型,但克服了以前生成模型的一些缺点,可以在理解和分类任务上也取得更好的结果,特别是会比T5和RobERTa 得到更好的效果。
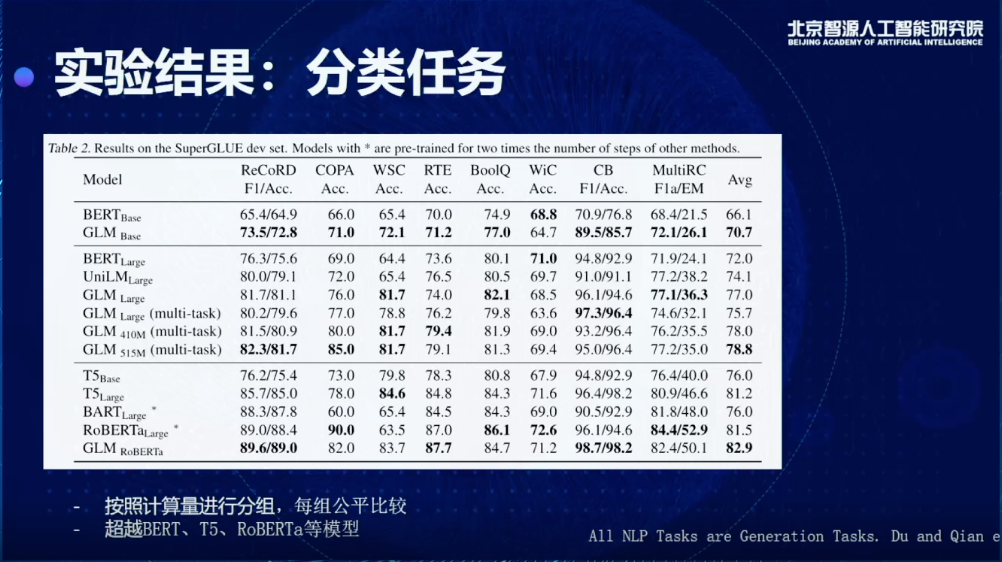
同时我们也测试了有条件无条件生成的情况下,会得到什么样的效果,一个比较重要的结论,现在可以用1.25倍的GLM模型同时在三个任务上取得最优结果,以前要做,要分别训练三个模型,对于超大规模来说也会非常限制模型的使用,这也是我们历史上首次实现单一模型同时在三种任务上取得最优的效果。
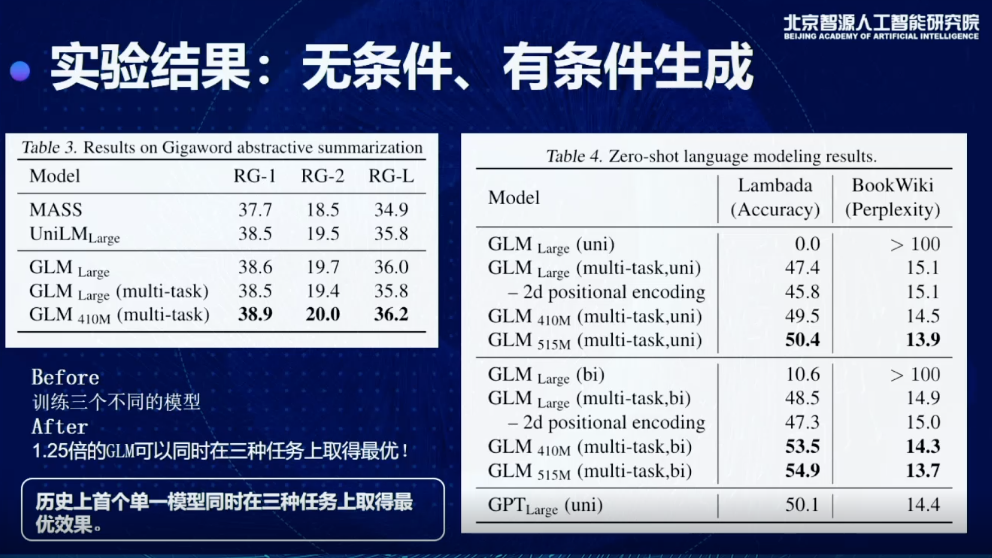
03
预训练模型如何做分类理解
讲完了底层的通用预训练框架,接下来会分享两个新的方法,这两个方法主要做的事情,就是当我有一个新的预训练模型时候,怎么去最大化它的价值,去最大化的抽取里面的知识或者最大化地优化它的少样本学习能力。

相关论文GPT Understands Too 的主要贡献者是刘潇、郑亚男、杜政晓、丁铭、钱雨杰、杨植麟、唐杰。(论文地址:arxiv.org/abs/2103.10385)
首先要从Prompt说起,比如现在我可以给这个机器这样的题目,比如X is located in Y,当X输入London,我们希望它预测Y是一个Britain或者其他的东西,那么这就是一个Prompt。通过Prompt的输入,可以实现少样本学习或者知识抽取的能力,也是目前比较流行的一种微调的方式。其实很经常做的一个方法,就是用一个手写的Prompt,相当于做特征工程,去做很多的尝试,手工从数据里构造各种各样的feature。

有了预训练以后,这部分时间要去做Prompt engineering。要花很多时间手写Prompt才能得到一个很好的结果,因为现在不同的Prompt只有细微的区别,有的只是增加减少一个词,但是performance最后会差四十个点,甚至更多,所以这种方式是非常难适应很多场景,而且在很多真实的场景下,比如说少样本学习的情况下,本来我们就没有非常大的验证集,就会造成一个问题,可能就是一个Over-fit的测试集,或者开发数据集,根本不靠谱。
后来,手写变成自动,当然是一个进步,但是还不够,始终是离散的,只要是离散的,就会面临这种variance很大的问题。我们这里提出来想做的是,想用连续的向量,去表示Prompt,通过自动地学习Prompt去得到更好的结果。
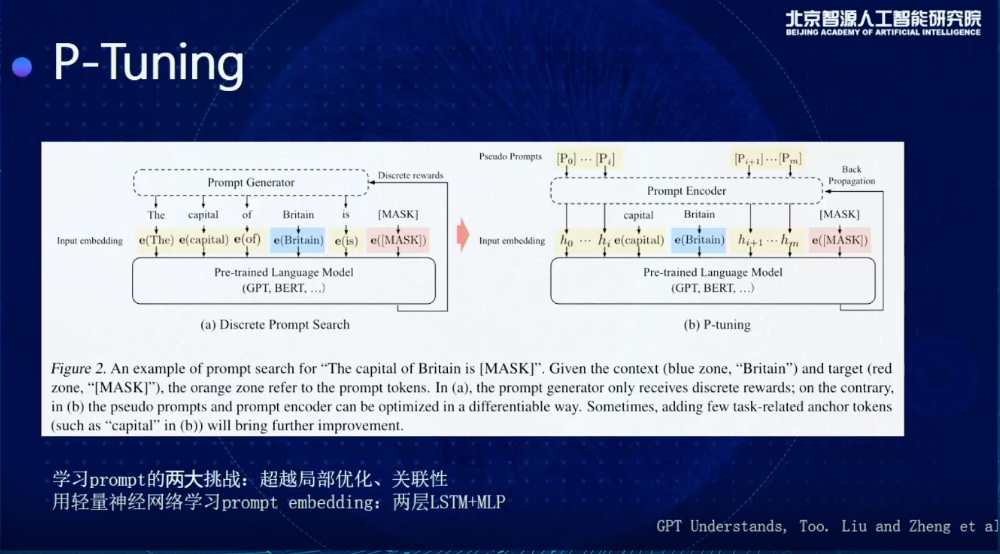
这是一个示意图,展示了我们怎么去做这个事情。比如这里面Prompt是The capital of Britain is....,可以填一个国家的名字,让这个模型告诉我英国的首都是哪里,传统的话可能会有很多离散的Prompt Generator会去生成离散的Prompt,但是右边,实际上可以用一个新的方法,给这个模型输入很多连续的向量,通过连续向量输入,直接在连续空间里寻找Prompt的最优解。
如果做到这样,需要解决Prompt学习过程中两个最大的挑战:
一个是局部优化,比如我原来是学到了很多初始的embedding,我可以在embedding基础上做很多微调,问题是通过SGD去优化,最多是在那个附近去震荡,但是很难搜索到一个比较好的结果;
第二个,我们希望这些Prompt embedding之间有一个很好的关联性,不希望每个独立地去学,为了解决这个问题,我们会额外地加一个Prompt encoder,不光去学一个trainable vector,加两层LSTM,加一个NLP,同时解决局部优化和关联性的问题,取得一个比较好的结果。
这个是我们在知识探测的任务上得到的一个结果,目前我们是最好能够做到64%,这个模型预训练完以后,在测试阶段不给他任何额外的文本,它不需要任何文本,它不是传统的知识抽取,我只要模型训练完,就直接从里面获取知识,这个benchmark,大概一年前,它的最好结果是20多,你抽出来的知识里,只有20%是对的,大概几个月前,大家优化到40左右,现在通过我们的方法,我们可以做到60%多,也就是说我现在这个模型在不给他任何额外文本的情况下,我就可以抽取出来60%多正确的知识。
这个里面,我们可以看到几个对比,比如说MP指的是我去手工写Prompt,P-tuning就是自动连续去调的方法,通过对比这两列,可以发现会有一个非常大程度的提升,比如在MegatronLM(11B)数据集上可以提升41个点,用RoBERTa-large可以去提升30多个点。

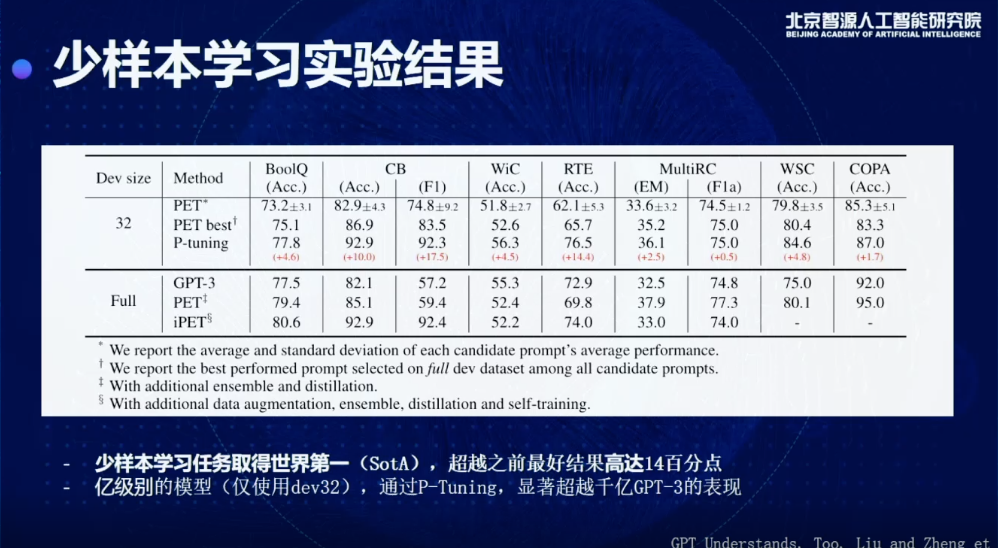
另一个问题,少样本学习非常重要而且也有非常广泛的工业应用,研究的是怎么通过少量样本,比如说20、30个,你就能够学到一个任务,而且这个任务的结果,和比如用一千两千甚至一万个样本可以得到到差不多的结果,实际上我们把这种应用放到很多NLP生产系统上,就可以极大程度地提升效率。
目前我们也是通过P-tuning的方式可以在Few-shot SuperGLUE上取得一个SOTA的结果,而且相比之前的方法,最高提升14个百分点,而且需要注意的是,我们现在用的模型,是个亿级别的模型,它只有几亿个参数,但它的效果已经比GPT-3在大部分数据集上有一个提升,GPT-3需要强调的是,当时开发的时候要用到完整的验证集,并不是真正的few-shot learning setting。我们这个是标准的few-shot learning的setting,在这种情况下,我们可以打败之前包括PET和GPT-3在内的所有few-shot learning的SOTA方法。
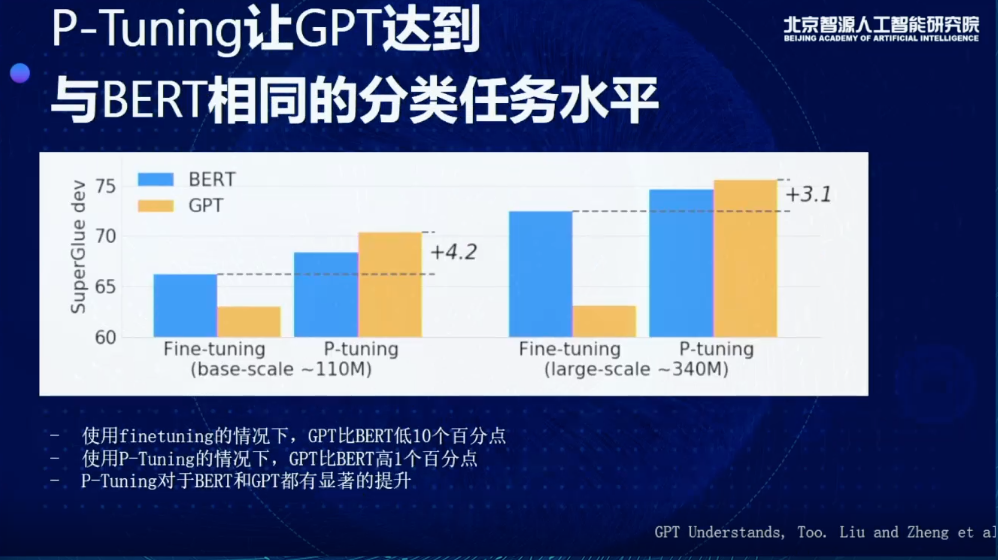
另外有趣的是,这个模型抹平了GPT和BERT在分类理解任务上的差距。由图可见,蓝色的是BERT的结果,橙色是GPT的结果,左边是Fine-tuning,右边是P-Tuning。当我们在用Finetuning的时候,不管是哪种scale,BERT都会非常明显比GPT更好,可能会好10个百分点。而使用P-Tuning的情况下,GPT会比BERT高1个百分点,且P-Tuning对于BERT和GPT都有显著的提升。
这大概是我们的第二个算法,主要是解决预训练模型怎么做分类理解任务。
04
基于Inverse Prompting的优化
第三个工作,Controllable Generation from Pretrained Language Models via Inverse Prompting,我们想分享的是在生成的时候可以做到可控。这个工作主要的贡献者是邹旭、殷达、钟清扬、杨红霞、杨植麟、唐杰。(论文地址:arxiv.org/pdf/2103.10685)

这里,我们从知乎摘了一个问题,去问我们的模型,说什么瞬间让你想留住这一刻?生成的句子非常通顺,但是实际上并没有在回答这个问题,也就是这个问题和答案关联性非常弱,这是一个普遍存在于预训练语言模型中的问题。

为了解决这个问题,我们就提出了一个新的方法,通过这个方法优化以后会生成:
一瞬间想到高二的时候,那天下午在操场晒了一中午太阳,和同学一起在楼下打球,下午的夕阳徐徐洒下来,我们三个人一起站在走廊上,倚着栏杆可以面对着夕阳。一直想留下那一瞬间,可惜我以后再也没有遇到过那样的时光。
这个回答还有点淡淡的忧伤。通过这种优化可以让回答和问题关联性更强,可以更好地通过Prompt控制所生成的内容。这是一个技术思路,核心的思路就是用生成的内容反过来用同样的模型预测原来的Prompt,这样的方式就可以保证这两个东西之间的关联性更高。把原来的Prompt的likelihood当成一个分数,在beam search的时候去重新rank里面每一个beam的分数,就可以实现这样的效果。
有了这个东西以后,我们发现它可以实现一些非常神奇的效果,这些效果可能以前的模型很难做到,比如我用现代的概念作古体诗。一般的语言模型能做的事情就是拟合一个文本,都是现代或都是古代的。但通过Inverse Prompting的方式可以把两种概念糅合到一起,这个模型真的可以捕捉到对象里面核心的特征,通过古体诗表达出来,特别是最后一句,若非王气起天壤,世界繁华岂易名,这跟我们当前的世界格局有一些关联。

下面这首诗写的是虹桥机场,这是非常现代的概念,古诗里从来没有,如果我学一个古诗的语言模型,根本不可能作出这样的诗,这首诗读来有一种孤独感和忧伤感,当然从诗歌专业的角度肯定会有一些瑕疵,但是你可以感受到非常深刻的孤独感,包括和虹桥、夜非常贴合,会有灯、月映水帘星、卢浦这样的意象。

还有咏相对论,引力张鞭势,牯牛曳著行,营造了一种科技感的氛围。

也可以写一些藏头诗,在beam search时可以固定藏头字,而且当你输入白话风格的标题时,它作诗的风格会相应地变化,带有强烈讽刺意味。

也可以回答问题,比如你问人注定要死为什么还活着?
它给了一个比较正面的回答:
我们活着的意义就是要寻觅人生的价值,体验生命的壮丽。为了追求这种生活,人们愿意奋斗终生。

这只是一些案例。最后我们还是要从量化的角度评估效果到底怎么样,所以我们找了很多人去看这个生成的结果,你就会发现相比于只用Prompting Baseline,分数会有很多提升。
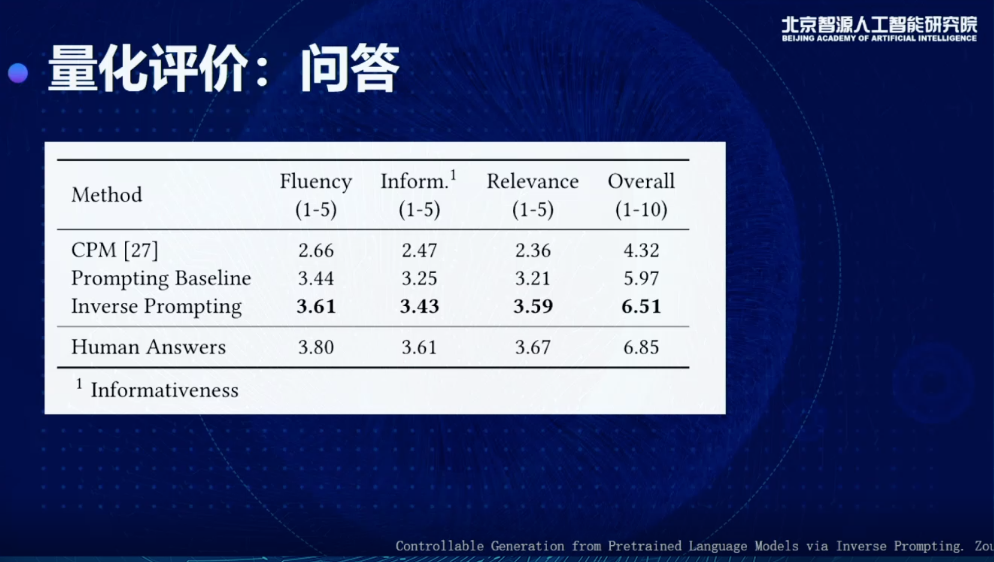
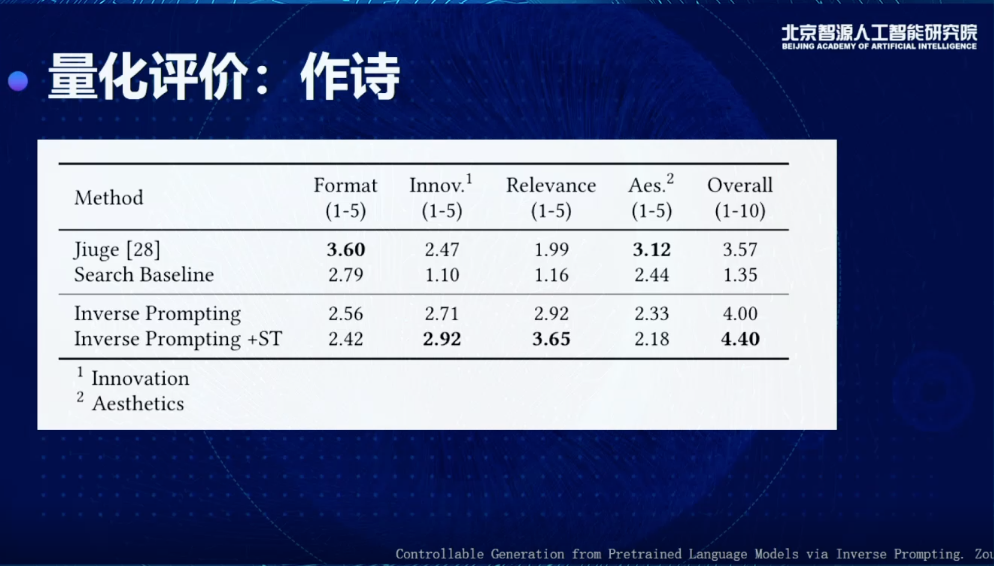
作诗上,我们从学校里找了诗社的人,让他们来衡量。和之前非常有名的九歌系统(Jiuge)做对比,发现各有千秋。九歌系统在韵律题材方面有一些优秀的地方,整体的评分会比搜索和Prompting这种基础方法有很大提升。
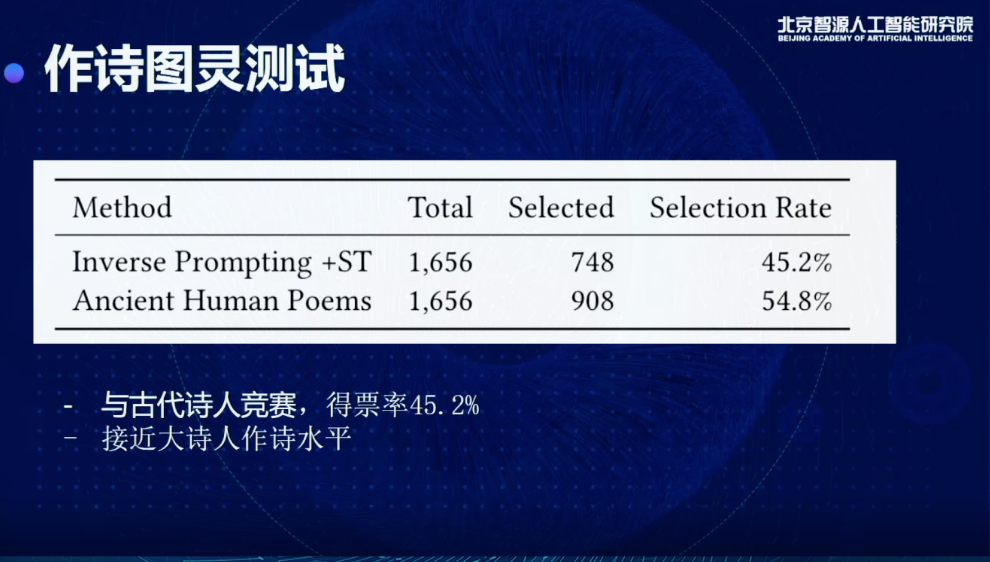
正如唐老师介绍的,我们还做了图灵测试,找了很多古代诗人真正写的诗,用它的标题去生成一些诗,可以看到有45%得票率,比较接近古代大师人的作诗水平。
总结
我们其实从三个方面,从技术的角度去做了一些突破,包括通用、知识和可控三个方面,从算法的层面去做了一些提升。长期来看,这三个算法只是第一步,往后还是要从更长期的角度解决问题,包括怎么去做决策,怎么真正完全少样本,以及这些代码系统怎么融合起来,去解决更多更难更大的问题,这都是未来要思索和探讨的方向。
© THE END
关于循环智能
循环智能(Recurrent AI)是一家 AI 企业服务公司,借助原创的自然语言处理和深度学习技术,帮助中大型企业充分挖掘对话数据的价值,提升员工产能,带来业绩增长。公司服务的客户主要在保险、银行、房产和在线教育等领域。创始团队来自清华大学、卡内基梅隆大学,并获得红杉资本中国基金、真格基金、金沙江创投、靖亚资本等知名投资机构的支持。2020年,循环智能获得高新技术企业认证,并被德勤Deloitte评选为中国明日之星50强。2019~2020年,循环智能连续两年入选《机器之心》年度最具产业价值榜单。
循环智能
增强“人”的智能
销售人员产能提升 | 销售预测与精准销售 | 新一代合规质检
↓ 详情扫码访问官网 rcrai.com

↓ 一键关注

