

























-620.svg)

语音识别新范式:完全的“端到端”模型优势在哪里?
-

2020-02-13
-

产品 · 技术 · 实践


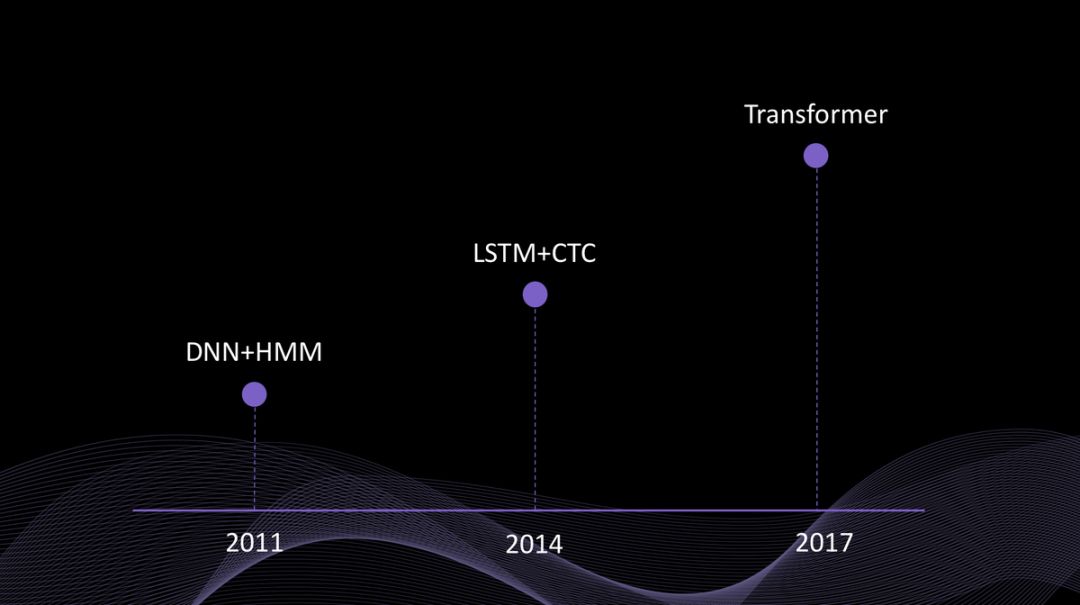
2011年前后,基于 DNN+HMM(深度神经网络+隐马尔科夫模型)的语音识别
2014年前后,基于 LSTM+CTC(长短时记忆网络+连接时序分类)的不完全端到端语音识别
2017年前后,基于 Transformer(自注意力机制)的完全端到端语音识别
第一,Transformer采用的自注意力机制是一种通过其上下文来理解当前词的创新方法,语义特征的提取能力更强。在实际应用中,这个特性意味着对于句子中的同音字或词,新的算法能根据它周围的词和前后的句子来判断究竟应该是哪个(比如洗澡和洗枣),从而得到更准确的结果。
第二,解决了传统的语音识别方案中各部分任务独立,无法联合优化的问题。单一神经网络的框架变得更简单,随着模型层数更深,训练数据越大,准确率越高。因此企业可以使用更大量的专有数据集来训练模型,得到相应场景下更准确的识别结果。
第三,新的神经网络结构可以更好地利用和适应新的硬件(比如GPU)并行计算能力,运算速度更快。这意味着转写同样时长的语音,基于新网络结构的算法模型可以在更短的时间内完成,也更能满足实时转写的需求。
2017 年 6 月,“Attention is all you need” 论文发表 ,Google 在这篇论文中介绍了 Transformer,一种基于自注意力机制(self-attention mechanism)的全新神经网络结构。短短两年多时间,该论文在 Google 学术中的引用量达 5956 次,毫无疑问是近几年自然语言理解领域影响力最大的论文之一。
2018 年 6 月,Google 发布了基于 Transformer 的 BERT 模型,被称为近几年 NLP 领域最具里程碑意义的进展。
2019 年 10 月,Google 在官方博客中宣布,已经将这项技术应用于搜索中,增强了对用户搜索意图的理解。
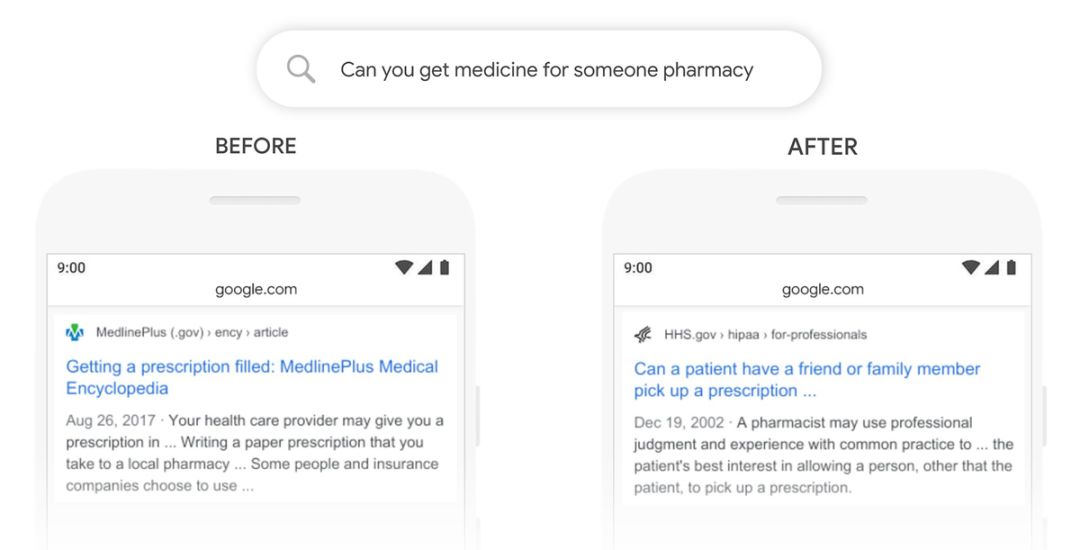
Google 搜索“可以帮人取药吗”的结果对比,新算法更准确地理解了用户的搜索意图,是想问能否帮人取处方药。
© THE END

↓↓↓

