






















-620.svg)


企业级ASR自训练平台 “谛听”
基于原创的、先进的 Transformer-XL 端到端基础模型,经过数百万小时金融、房产、汽车等行业标注数据训练,支持多场景的声纹识别(角色分离)以及基于深度神经网络的语音降噪技术,可为企业定制专属模型。
-

模型自训练
-

多场景声纹识别
-

深度语音降噪
循环智能ASR和语音技术优势
-

 原创底层算法模型
原创底层算法模型循环智能联合创始人杨植麟与Google、卡内基梅隆大学,合作推出国际前沿的原创算法模型 Transformer-XL,并在全部六个主流语言建模数据集上夺魁。循环智能率先将该模型应用于企业级语音识别系统,实现准确率更高的端到端语音识别。
-
 深度定制化模型
深度定制化模型提供从“热词”到“语言模型”和“端到端模型训练”的多层次模型自训练定制服务,可一键实现定制化ASR模型训练。通过和业务系统打通,实现数据标注、筛选、导出、训练闭环,并提供模型仓库对模型版本进行管理,效果指标可追溯,一键部署上线。
-
 高精度角色分离
高精度角色分离因为节省存储成本的考虑,很多企业采用单轨录音。循环智能提供1:1声纹匹配和1:N声纹检索能力,准确率90%+。在不指定说话人个数的情况下,可以准确的进行说话人角色分离,适应电话、视频会议、线下沟通等各个场景。
-
 深度语音降噪
深度语音降噪传统降噪方案无法应对复杂真实场景的非稳态噪声和瞬时突发噪声。循环智能基于深度神经网络的降噪模型已适配数千小时上千种各类环境噪声,可满足各类使用场景。
-
 实时方言自适应
实时方言自适应在语音识别过程中,循环智能的ASR模型可以以句子为单位,实时判断当前的方言和语种,并实时选择最合适的ASR模型进行识别
-
 全栈AI语音能力
全栈AI语音能力不仅提供包括流式语音识别、长语义识别在内的语音识别算法,而且提供全套自研的全栈AI语音能力,包括说话人分离、声纹验证等声纹相关算法、智能降噪和声源定位等信号处理算法。
-
 自研麦克风阵列技术
自研麦克风阵列技术循环智能自研的麦克风阵列专利技术可以定向增强特定方向的声音,过滤周围的噪音;可同时对两个方向进行波束成形,定向拾音,实现实时角色分离,满足柜台、会议室等线下场景复杂的收音需求,软硬一体方案,即插即用。
-
 一站式语音数据接入
一站式语音数据接入在呼叫中心场景,提供旁路语音流、镜像抓包、SIP代理三种接入方案,满足不同IT架构需求;在传统固化场景提供软硬结合的方案,实现低成本的数字化升级;音视频会议场景自研RPA方案;线下场景提供软硬一体数据采集方案。
-
 支持私有部署
支持私有部署中小企业可以选择 SaaS 模式,也可以选择本地的私有部署或者云端的私有部署模式。我们将根据实际业务量,即每日电话录音时长、实时转写的并发数,为您推荐高效的云端或本地服务器配置。


ASR自训练平台架构
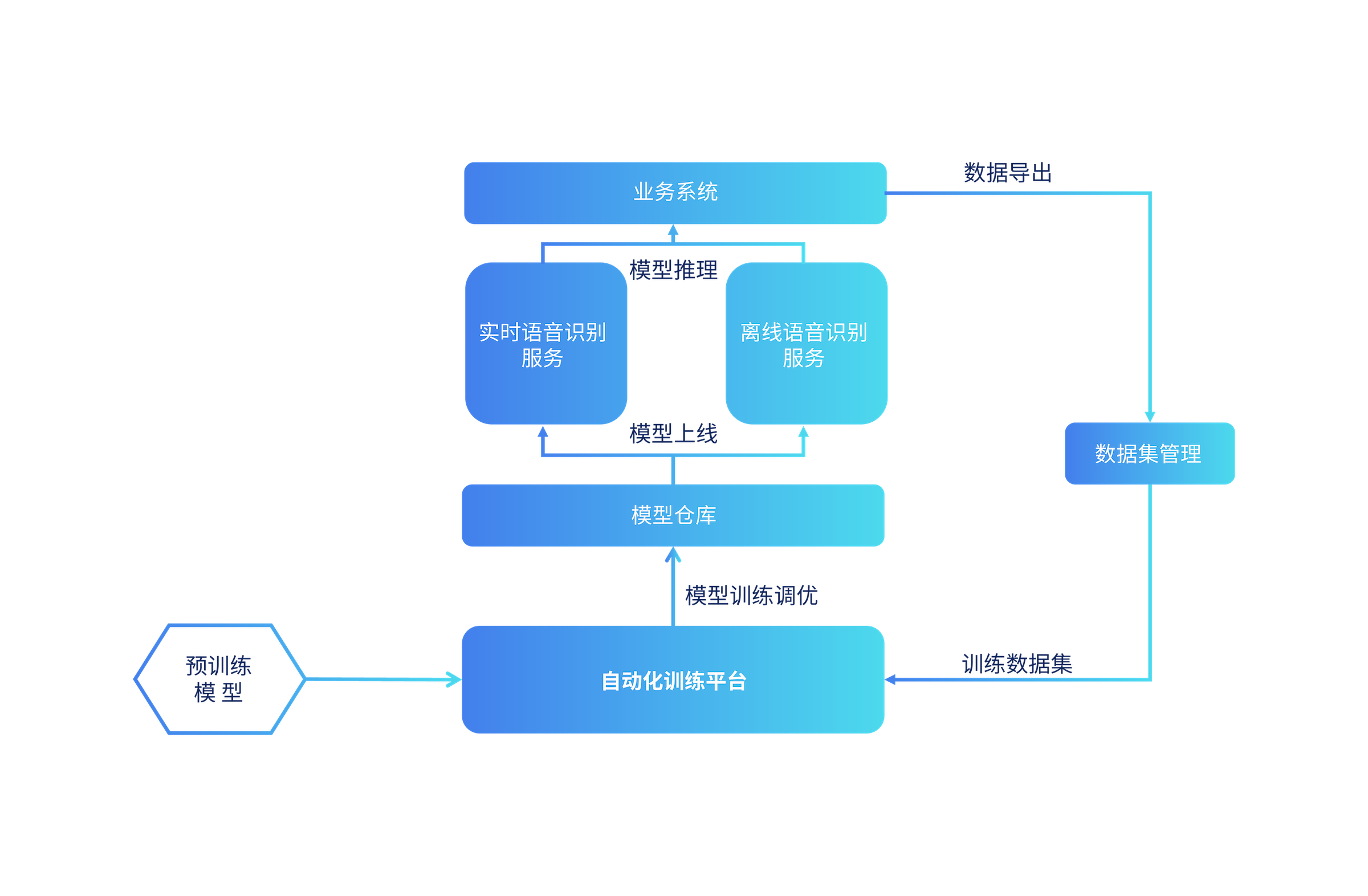
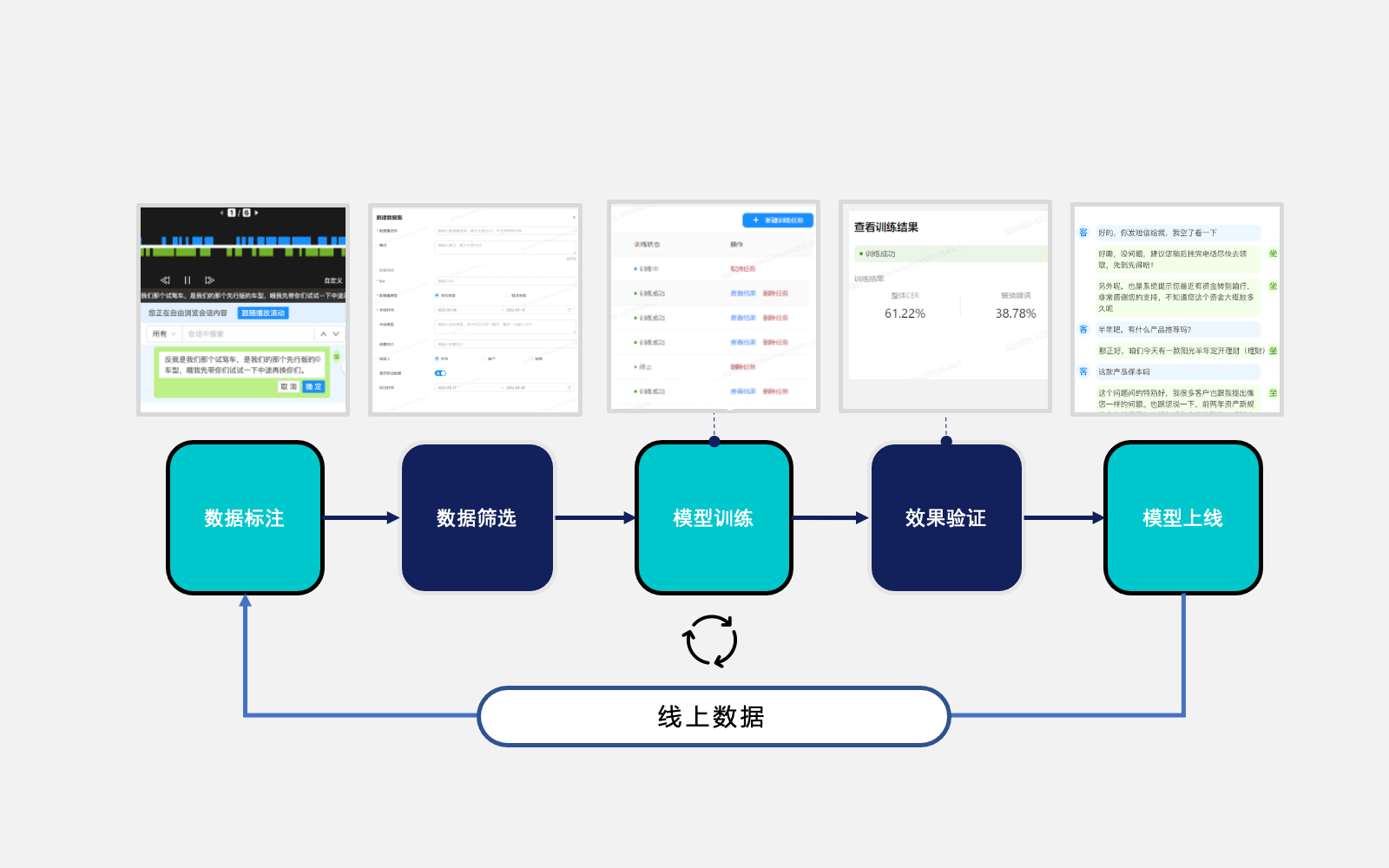
ASR自训练主要流程
在技术专家、标注人员和运营团队的通力合作下,借助标准化的ASR模型自训练系统,可快速生产和管理定制化的ASR模型。
-
1
数据标注
-
2
数据筛选
-
3
模型训练
-
4
效果验证
-
5
模型上线
-
Step 1数据标注
人工标注修改基础机器模型转写的文本
-
Step 2数据筛选
筛选已标注的数据,新建数据集
-
Step 3模型训练
PTuning微调和Badcase优化
-
Step 4效果验证
提供模型查询、同步预测和异步预测接口
-
Step 5模型上线
选择相应的模型上线正式使用

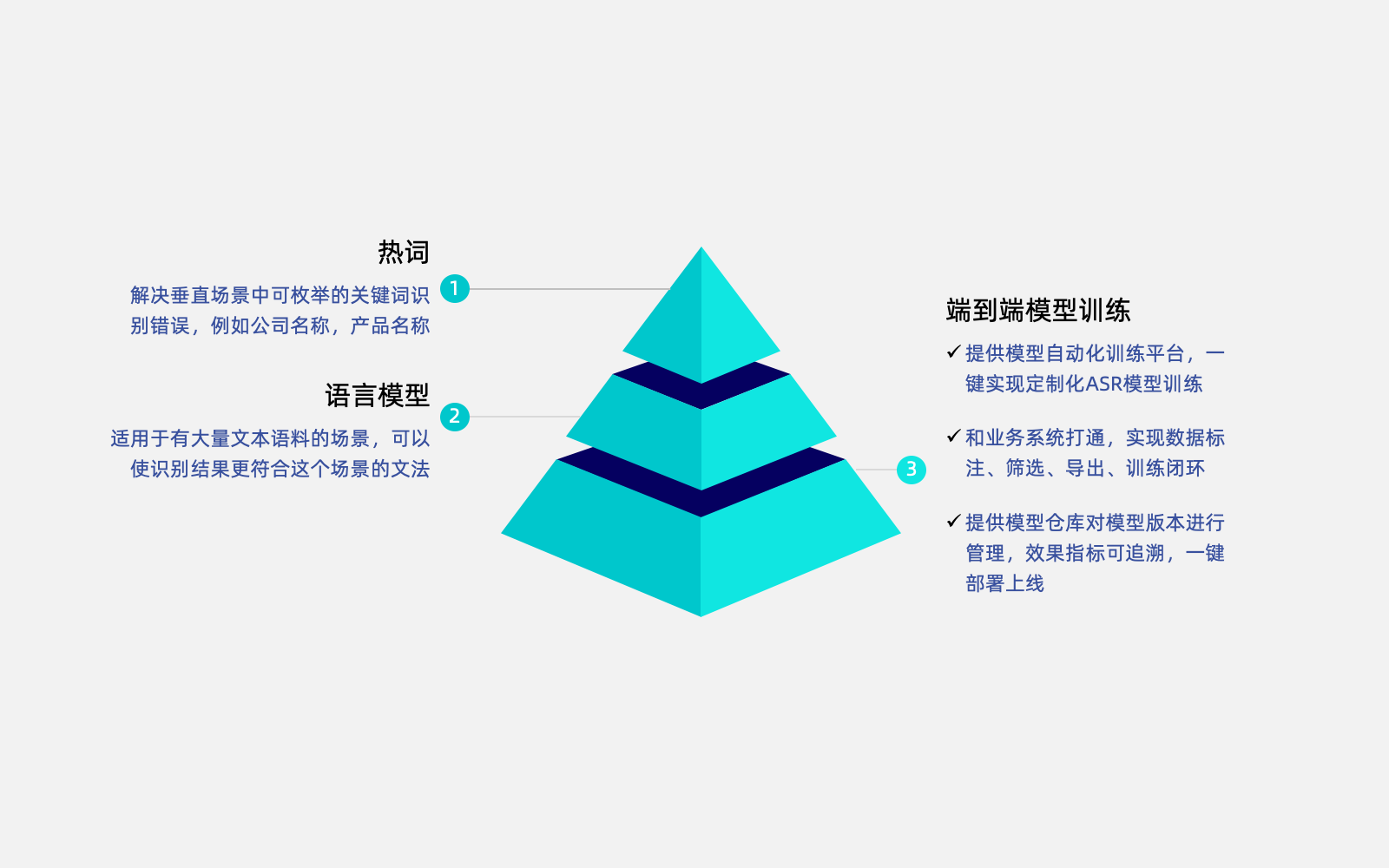
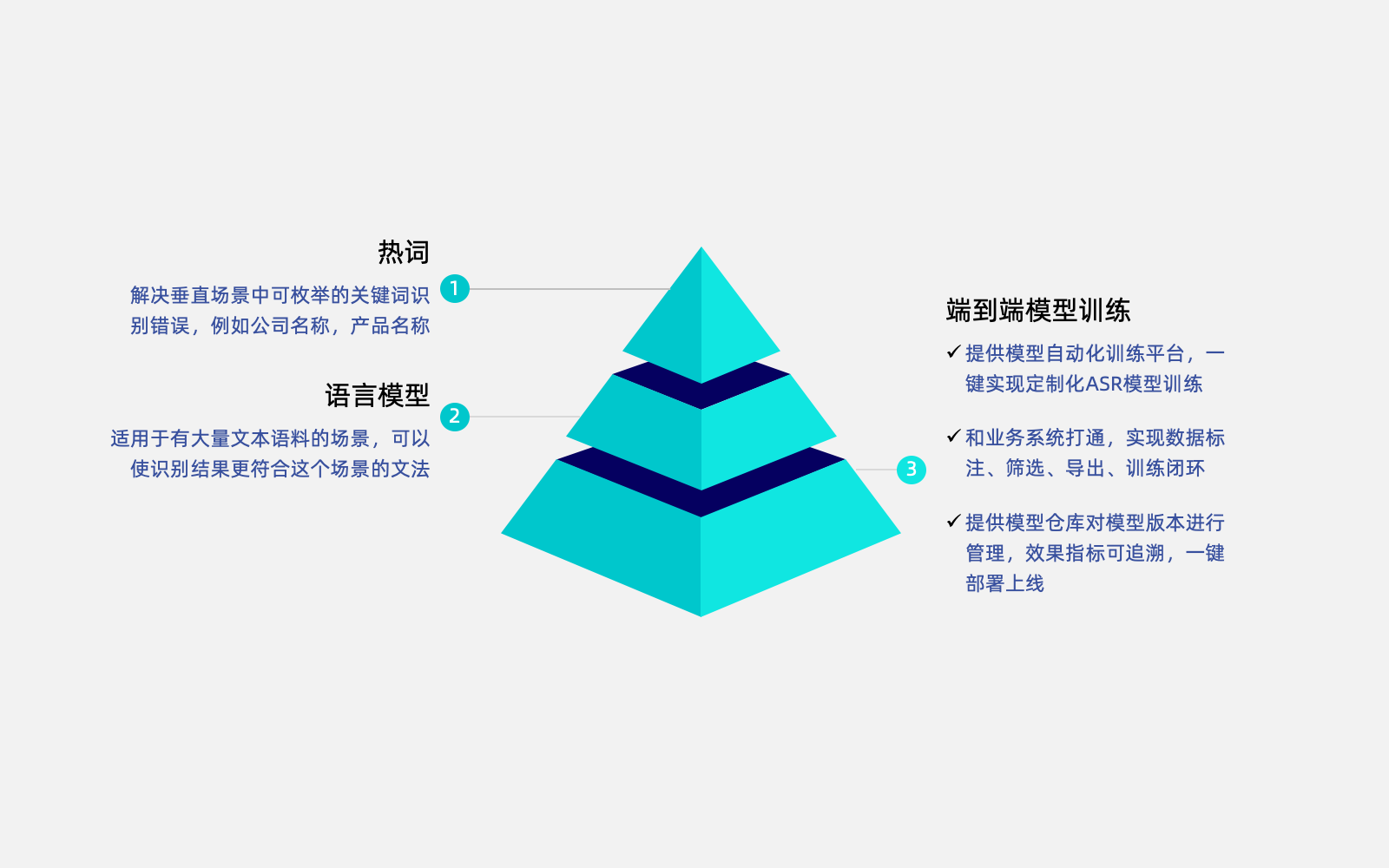
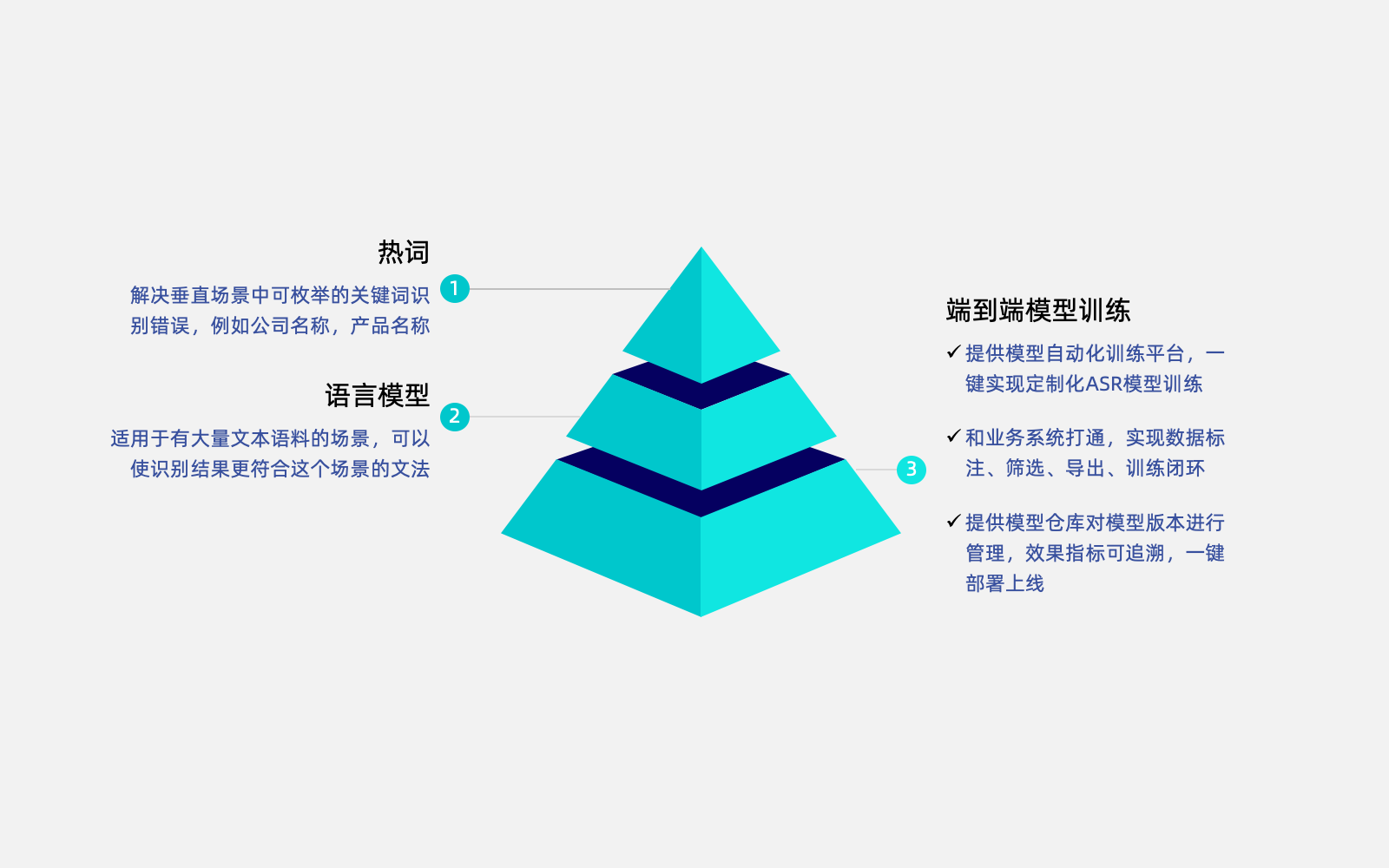
垂直场景ASR模型定制调优方案
针对业务需求提供三个层次的模型优化
-
 一、热词
一、热词解决垂直场景中可枚举的关键词识别错误,例如公司名称,产品名称
-
 二、语言模型
二、语言模型适用于有大量文本语料的场景,可以使识别结果更符合这个场景的文法
-
 三、端到端模型训练
三、端到端模型训练提供模型自动化训练平台,一键实现定制化ASR模型训练
价值提升的适用场景
-
呼叫中心
提供旁路语音流、镜像抓包、SIP代理三种语音流对接方案,可以适配不同IT架构的需求


-
金融柜台
软硬一体方案,场景专属定制硬件,即插即用

-
会议室
基于自研硬件实现线下远场录音采集和语音增强,多角色分离算法,实现不指定人数情况下的准确语音分离

-
车内
使用基于神经网络的语音降噪模型,可以在消除车内噪音的情况下尽可能完整保留对话语音

-
线下门店
利用麦克风阵列和声纹相结合的技术,对语音进行降噪和准确的角色分离










众多行业客户的信赖







































































提升你的销售与客户经营效率,就是现在
循环智能的解决方案专家可为您远程或上门演示产品

