






















-620.svg)


盘古NLP大模型
盘古大模型是业内首个千亿参数的中文大模型,拥有1100亿密集参数,经过40TB的海量数据训练而成。同时也通过多任务prompt等技术延伸出10亿参数、性能更好的落地版本,极大地加速了AI的商业应用效率和泛化能力;
盘古大模型的算法由循环智能主导和清华大学、华为的算法团队联合攻关,在预训练阶段引入基于Prompt的任务等多项创新方案,成功突破了大模型微调的难题。
-


多行业领域
-

多任务类型
-

中文大模型
-

零样本学习
AI落地难的行业痛点
-
 标注数据量大
标注数据量大模型训练所需数据量大,而数据标注依赖于昂贵的人工成本。

-
 研发成本高
研发成本高AI模型研发成本极高,开发、调参、训练、优化均需专业的算法研究人员。
-
 优化周期长
优化周期长由于数据所需量大,标注周期长,严重降低了模型的迭代速度,效率非常低。
-
 泛化能力差
泛化能力差单个模型只可应对单个领域下的单个任务,业务种类多时,需多个模型来应对。
盘古NLP大模型的优势
盘古的零样本、小样本学习能力强,可极大程度的减少数据的标注成本。
相比传统调参方式,盘古通过自动化prompt的方式极大的加速了模型迭代速度,开发成本大幅降低。
由于不需要大量标注数据,且不用反复进行调参实验,可实现盘古大模型的快速优化迭代。
盘古大模型可同时应对多个领域的多种任务类型,如金融、房产、教育等不同领域。
平台采用全新的交互形式,设计简约,流程清晰易懂,无需算法背景,通过拟人对话的形式创建并测试模型,简单培训后可迅速上手构建企业自己的定制模型。
-


零样本学习
-

研发成本低
-

优化迭代快
-

泛化能力强
-

可快速上手




基于预训练的NLP技术演进到第三阶段
盘古大模型采用了最新一代技术,经过循环智能和华为的算法研究团队的数月联合攻关,通过Prompt将下游监督任务加入预训练阶段,
采用超多任务的大规模预训练方式,大幅降低了微调难度,解决以往大模型难以为不同那个行业场景进行微调的难题。
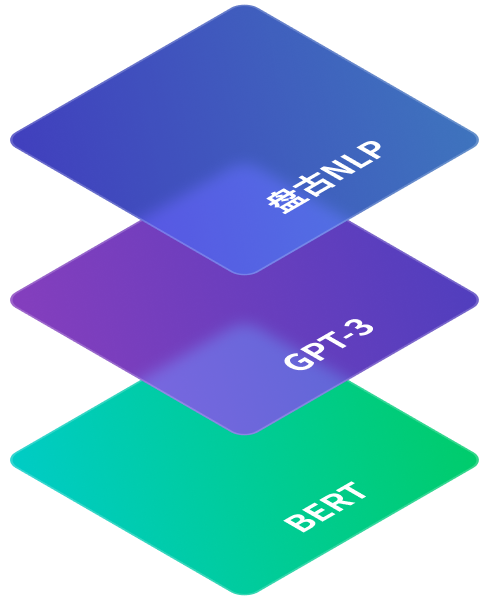
以盘古NLP大模型为代表的半监督预训练+超多任务的大规模预训练+自动化prompting

以GPT-3为代表的“超大规模预训练+prompting”范式

以BERT为代表的“预训练一微调”范式


超大规模模型带来的流程变革




盘古NLP大模型的落地能力
联系我们,即刻体验盘古超能力
循环智能的解决方案专家可为您远程或上门演示产品

